The Perils of File Typing
Published 2020-12-06
The Perils of File Typing
Corrections added to the Creator/Type code section thanks to user "Somebody" on Hacker News
Suppose you double-click on a file on your computer. You're doing this so you can open the file and work with it. But does your operating system know what that means? How does it know what to open the file in? Let's look at some solutions that have been proposed over the years to solving this issue.
(fun fact: this originally started as a touchup of one of my oldest articles before just kinda becoming this whole thing, so expect a bit of retreading.)
Nothing

Used in: Early mainframes such as the IBM 704, etc.
(Image credit: Lawrence Livermore National Laboratory)
What's a "file", anyways? It's a sequence of bytes on a disk, possibly floppy. Or a tape. (Cassette or paper, your choice.) Or on stacks of cards with holes in them. Or toggled in by hand on a front panel.
File types weren't relevant because files weren't really a thing. In the mainframe era, you typically 1. loaded a program on to your computer from punch cards or a tape 2. fed input into that program either from a teletype terminal or from a different tape/card deck 3. received output from the teletype, a line printer, or yet another tape/card deck
Computers weren't complicated enough where there was any confusion as to what a file on a certain medium was, simply because there was so little to work with. If you had a stack of punchcards, that was your "file". Hope you labeled the box you put it in!
Tapes are more interesting, because they hold substantially more data. (A whopping 5.76 megabytes, stored on 3/4 of a kilometer of magentic tape. How exciting!) That said, storing more than one file on a tape was a strange task. Operating systems weren't really a thing yet. The best that existed were programming languages such as FORTRAN or COBOL that had statements for hardware tasks such as reading from or writing to a tape or punch card. For example, here's the manual for FORTRAN for the IBM 704. We have several commands such as READ (from the punch card reader), READ TAPE, PUNCH (new cards), PRINT (to the printer), etc.
On the IBM tape units of the time (ex: the IBM 727), tapes were separated into files and records. In FORTRAN, records were created on every WRITE TAPE command, and could be read with READ TAPE later. Records could be overwritten by using the BACKSPACE statement and then writing again. Files were collections of records, and could be created with an END FILE command.
As an aside, later programming languages such as C still share their heritage from this era. This is why we draw text to the screen with printf which long ago would have literally printed to a teletype terminal, why we read files using rewind, fseek, fread, and fwrite as if we were on a tape drive still. Even ASCII, the encoding most commonly used for the basic Latin alphabet, has code points for file, group, record, and unit separators. (This may also be related to block terminals, something that will be discussed in a future article.)
As mainframes moved onto more advanced batch processing and later interactive time-share operating systems like UNIX, OS/360, Michigan Terminal System, ITS, etc., they gained more sophisticated methods of dealing with files than raw tape drive access. But then came the microcomputers.
Type Codes
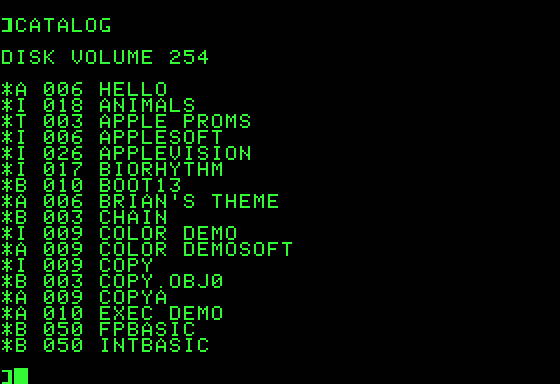
Used in: Apple DOS for Apple II (1978-1980), HP-28 and HP-48 series, etc.
We have floppy disks now. They can store a lot of files, rename them, delete them, etc. without too much issue. There's this neat computer called the Apple II that just came out. It uses these new-fangled disks, so it needs to figure out how to store files on it.
The way that Apple DOS (the Apple II's disk operating system for most of it's life) stored files is somewhat interesting. Each file has a name (up to 30 characters) and also a type code. 8 of them were defined but only 4 of them mattered:
- I (Integer BASIC program)
- A (Applesoft BASIC program)
- B (Binary files; either assembled programs or data)
- T (ASCII text files)
Apple DOS had some specific commands that interacted with these types. For instance, the RUN command worked on both Interger BASIC and Applesoft BASIC programs, and chose which one to use. BRUN, binary run, only worked on binary files. OPEN, READ, WRITE, and CLOSE all worked only on ASCII text files.
The types more served as a way to help the operating system more so than you. This is especially evident in the late 80's and early 90's HP calculators such as the HP-28c and the HP-48GX. These calculators didn't have disks, but they did have persistent memory that could store objects into folders much like a computer.
These calculators used Reverse Polish Notation. Essentially, you do math by placing objects on the stack and then executing commands, which take things from the stack and put a new thing on. An object in RPN is something you placed on the stack. The HP-48's Advanced User's Reference Manual lists 32 distinct types, including real numbers, complex numbers, character strings, arrays, lists, variable names, executable programs, graphics objects, directories, etc. A command could be, say, ADD or some fancy plotting calculus stuff. Whatever they were, they needed to know what types they were dealing with so that they could either reject the input or properly work with it.
Like the Apple II, just having an integer for a type is perfectly okay because the types don't serve the user. They're just there so the operating system knows what a given chunk of bytes on the stack is. There are a few reserved spots for custom types, but for the most parts new types aren't expected to ever be added, nor should they be.
File Extensions
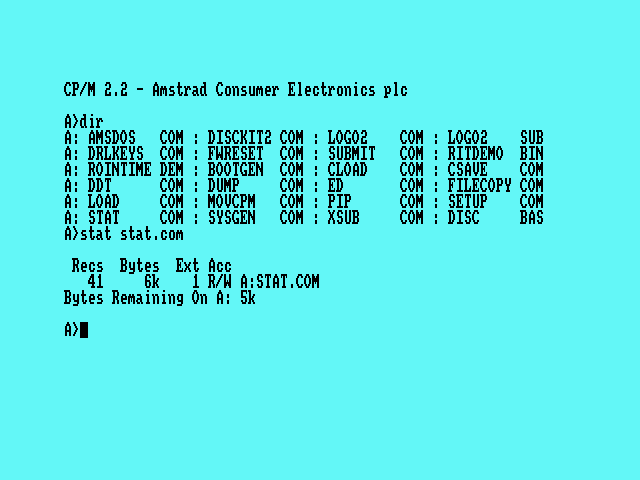
Used in: AMSDOS (Amstrad CPC), CP/M, MS-DOS, etc.
Microcomputers really started to gain in popularity with the likes of the ZX Spectrum, the Amstrad CPC and the Commodore 64 among others. These were fairly cheap and simple computers. When first launched, these came with nothing but cassette tape inputs, as disks were too expensive.
On these computers, you'd attach a cassette player using a standard AUX cord (although some, like the CPC, had a cassette player built in), and the computer would instruct you when to start and stop the tape. These cassette players usually came with a little counter that rolled up as the tape progressed, to help you tell where the tape was. When you insert a tape, you reset the counter to zero. When you want to make a file, you'd write down what the counter read, then save the file. To load a specific file, you'd seek the tape until you're at the location you've written down, then start reading.
More advanced computers such as the Amstrad CPC instead saved a header with each file containing, among other things, a file name and extension. If asked for a specific file it could just read the tape until it found it. Later these computers gained disk drives, and any ad-hoc tape fiddling was replaced with a proper file system such as FAT or MFS that stored where a file was on a given disk and what is was called.
File codes are limited. It is nigh-on impossible to add more ones. What you have is what you got. So... what if we just made the codes out of letters? A couple of them? And they could be anything. Then programmers could come up with whatever file extensions they want and that's okay.
Suppose, in MS-DOS, you have a file named REPORT.TXT. REPORT is the file name, TXT is the extension. File extensions give an easy, consistent indicator of what a file contains. A TXT file contains text, a BMP file is a bitmap, etc.
Some file extensions, like EXE, BAT, SYS and COM had special meaning much in the same way that the Apple DOS codes had special meanings, but other than that they're just there to help the user. The user had to manually choose which program to use. This allowed for the user to choose what view or editor to use depending on what would be the most helpful. Unfortunately, there were no default programs. If the user didn't know which program, say, a VIZ file is for, they're out of luck. Is it a visualization? Some manga thing? The digital manifestation of a cute internet ghost who's staying up way too late geeking out about old computers? The world may never know...
Creator Codes
Used in: Classic Mac OS
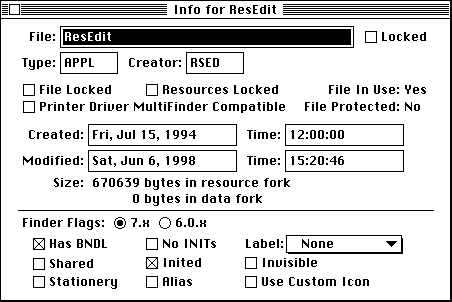
Let's hop on over to the Macintosh for a quick second. It was a newfangled thing in 1984, and it had the opportunity to reinvent the wheel and break compatibility with CP/M and mainframe traditions. And so it did.
The original 128K Macintosh used 400K floppy disks, a not-completely-terrible amount of space for the time. It used the MFS, which didn't support directories but did support files. It was also completely graphically driven. The Finder was supposed to be the primary way of interacting with files, and the File > Open command could launch the program that made the file. How'd it do that?
Instead of file extensions, the Macintosh used type and creator codes. These were 4-byte identifiers, much like file extensions, but there were two of them each with a different meaning. The type code was mean to represent the format the data was stored in, used to filter files in the Finder's "Open" dialog. The creator code was meant to indicate the application that created the file, and used by the Finder to choose which specific application to launch. Now, these weren't normally visible to the user. They just saw the file name and a icon for that type.
To do that, the system kept a database of codes and their associated icons and programs. When ran for the first time or moved from disk to disk, the Finder would read the program data and register in a database what creator codes and file types it supported. The Finder would then save this information on the disk containing the application. Later, when the user opened a file, the OS would check its type and creator code against its stored list to determine which application to use. This worked pretty well.
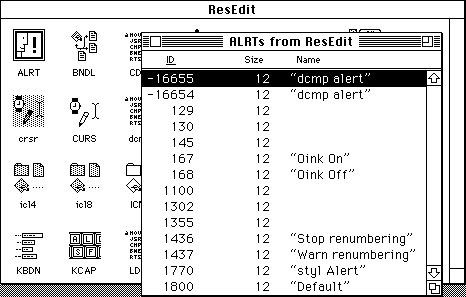
A similar system was used for Macintosh resources. Within each file was a list of resources, grouped by four-letter type and then by numeric ID and an optional name. This approach is much more like a database than a filesystem, and it serves its job well at the cost of being inflexible. This is fine for an internal database of program resources, but less file for files the user wants to sort and organize.
One downside of this approach was that it had very poor interoperability with other operating systems. Almost any file sent over the internet had to be BinHex'ed or StuffIt'd to preserve both the resource fork and the type/creator codes. This was a bit of a pain to work around. Later versions of Classic Mac OS included a list for conversions between type/creator codes and Windows-style file extensions, as those seemed to be the most reliable way to determine some kind of file type information.
File Associations
Fast forward to about Windows 95 or so. It had a problem. It wanted to steal some pages from the Mac, to make the operating system more file-centric... but that's not how Windows 3.1 or DOS worked.
The DOS way of doing things was still inspired by the old mainframes and micros. Load a program, do what you need in the program, quit. What Windows 95 wanted to do was to create a document-centric workflow where the application was out of the user's way and it only provided the means to let the user manipulate files.
It needed to somehow take this file-centric workflow and bolt it onto application-centric DOS. Files needed to be tied to extensions, somehow. It was unreasonable to attach type or creator codes, or to omit extensions, because that would break compatibility.
Instead of tying a file's type to the creator/type codes, Windows 95 instead used the already existing file extension. Applications, when installed, could register what extensions they supported and how to display them in the file manager. When a file was opened in the file manager, Windows would open that file in the registered application. Simple enough, right?
If the operating system always knew what program to open a file in, and it has a friendly name and icon to show the user for a specific type... did we need to show the file extension? The Windows 95 team decided to hide the file extensions, as they would only serve to confuse the user. In my opinion, this was a terrible idea. Why? MS-DOS.
The three-letter extension was fairly limited, and wasn't a very reliable indicator of what a document was. At best, a file extension at best indicates what format a document was stored in, not what kind of file it is. For instance, the format of a file could be an image, but the kind could be a photograph, or pixel art, or a document scan, or any number of other things. Some applications may save to the same format, but handle radically different kinds of documents. You would not use a pixel art editor to touch up a photo.
Windows 95 could not and did not account for this beyond the "Open With" menu, which allowed the user to choose an application. However, the goal was to let the user think in terms of file, not applications. On the other hand, the Macintosh could have files of the same format registered to different applications because of the Creator code. It's not a perfect solution (what if the user wants to do something else with the file?), but for most use cases the extra information helps.
Additionally, hiding the extension led to some real head-scratchers. If two files had the same name and different extensions, they would both be displayed with the same name. If the icons were the same, telling them apart was difficult. The most common example is on the root of an installation CD, where an icon file could be stored next to the installer, both with the same name and icon. The only way to tell them apart was to read what types were listed for each file.
Another bad example was misleading file types. Suppose you have a file, Picture from Grandma. It looks like a picture, it has the picture icon. But when you open it, it infects your computer with a virus. As it turns out, the picture wasn't a picture but a program with the picture icon. In my opinion, hiding type information is more dangerous and comfusing than omitting it. (For what it's worth, the Macintosh was suspectable to this sort of attack as well, and anti-malware scanners will stop these dead in their tracks. But this was a problem for a long time.)
Magic Numbers
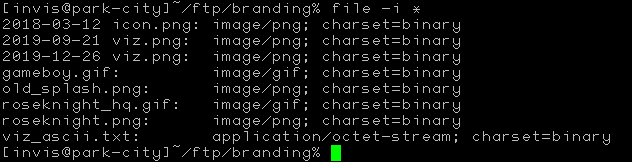
UNIX and Linux never had a concept of type codes or file extensions. A file name was just a file name. The user was expected to know what kind of file it was. This was very similar to the mainframes and minicomputers that UNIX was born from. There was nothing stopping them from adding their own extensions, though. There just wasn't any specific OS support for them..
Later, it was decided that this was a silly idea. However, there was no way to add type information to a file. Instead, programs were written to look at a file type's magic numbers. These are short identifiers in a file that signal what type it is. If you're on Linux or Mac OS X, you can actually try this out by opening the terminal and running the file command on whatever you have laying around.
To an extent, this is nice because it doesn't matter what the extension is, or if it even has an extension. There (in theory) is no way to misrepresent a file's type. But there are problems to this approach.
- Checking a file's type becomes a computationally expensive process, compared to just checking if some letters match.
- Some file formats may not have magic numbers
- File formats don't indicate what a file's kind is, what type of data the file actually contains regardless of format.
- Some file formats are based off of other file formats (ex: Firefox extensions and Word documents are both ZIP archives.), which makes analysis complicated.
- Some file formats might be two distinct formats at the same time! This includes maliciously constructed polyglot files as well as, ex: installers that contain ZIP archive data.
That's not to say they don't have their upsides. Given a random, unnamed or mis-typed file, you can easily recover the type. But I've come to the conclusion that they're too fragile and brittle to be effective for everyday use across all file types.
MIME types and Uniform Type Identifers
As the internet started being a thing, people needed a standardized way to define the format of a file. Enter the MIME type. These are primarily used on the internet to signal to a web browser or email client what type a file is, but they're used in other contexts as well.
For instance, a text file is an text/plain, and an image could be a image/png. MIME types are usually considered the authoritative, machine-readable answer to "what type is this file". Most Linux distributions ship with a shared MIME-info Database, which contains mappings from MIME types to magic numbers, icons, names, alternate MIMEs, and any types they inherit from. This database is fairly comprehensive, containing just about every file format worth cataloging.
That said very few operating systems actually store MIME types, even though they are capable of doing so using alternate data streams or extended attributes. MIME types are almost always derived from file extensions or magic numbers. They also still don't solve the issue of kind vs. format.
Later versions of macOS (10.4 and later) use a Uniform Type Identifier internally. These are basically MIME types, but with a nicer format. Here's a big list of them. These are defined in a rather nice way, where types can be specializations of another, more general type, unlike MIME which only stores what formats a given format extends from. (ex: an MP3 is an audio file) This allows for easy searching by type. (ex: find all audio files)
So what's the best?
It really depends on context. Why you're asking the question, what devices you're talking about, etc. Here's a quick list on what I think the pros and cons of each strategy are. Feel free to choose whatever is best for your purposes.
Nothing
Good for:
- embedded systems with no real file system
- very controlled environments where input and output are always known
Bad for:
- when you actually need the type of a file
File Extensions
Good for:
- Simple implementations
- At-a-glance hassle-free format identification (usually)
- Backwards compatibility
- Mis-typing errors are easy to correct
Bad for:
- Reliable file associations
- Determining the kind of a file
Type and Creator Codes
Good for:
- Simple implementations
- Automatic and easy file associations
- Preserving format and kind
Bad for:
- User transparency
- Potential mis-typing errors are hard to correct
- Difficult to implement in modern operating systems
MIME Types
Good for
- Being reasonably consistent, well-used, and documented
- Internet transport
- Recovery when no file type information is found (via magic numbers)
Bad for
- Being easy to attach to files
- Being readable by humans
- Determining the kind of a file
- Reliability, if relying on magic numbers